
Mental health disorders such as depression and PTSD continue to present major global healthcare challenges, while traditional assessment methods remain limited by subjectivity, recall bias, and restricted access to specialists. This paper introduces a multimodal machine learning framework that analyzes text, audio, and video interview data to support more objective and scalable mental health diagnostics. The study evaluates how different embeddings, preprocessing formats, deep learning architectures, and classifiers influence diagnostic performance, with strong results on the E-DAIC benchmark.
Main Contributions
This paper makes several important contributions to multimodal mental health diagnostics:
1.Multimodal analysis: It evaluates the role of text, audio, and video modalities in detecting depression and PTSD.
2.Data formatting strategies: It studies both full-interview and chunked question-answer formats, showing that input structure can strongly affect performance.
3.Embedding model assessment: It compares multiple embedding models for text and audio, including OpenAI text embeddings, Google text embeddings, Whisper, and wav2vec.
4.Feature extraction design: It explores MLP, CNN, BiLSTM, and CNN-BiLSTM architectures for extracting richer modality-specific patterns.
5.Classifier improvement: It shows that replacing the final MLP classifier with SVM improves performance in several settings.
Methods
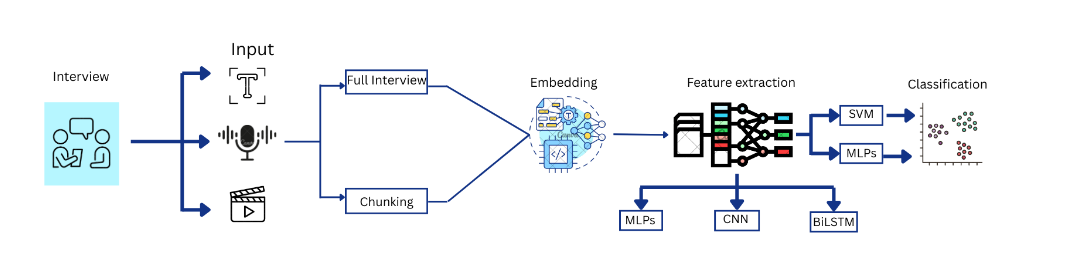
The proposed framework processes interview data through a multimodal pipeline that includes preprocessing, embedding extraction, feature learning, and classification. The study first evaluates different data representations for each modality, then selects strong embedding backbones, applies neural feature extractors, and finally tests hybrid classification with SVM to improve generalization and decision boundaries.
Data and Preprocessing
The experiments are conducted on the Enhanced Distress Analysis Interview Corpus (E-DAIC), which contains text, audio, and video data from semi-clinical interviews. The dataset includes 275 samples, with labels for both depression and PTSD. Text transcripts were produced using Whisper v3, audio was analyzed both as full interviews and segmented responses, and video relied on OpenFace-extracted features included with the dataset. The study also evaluates question-answer formatting, chunking, and overlapping sliding-window strategies to better preserve conversational flow and temporal context.
Embedding and Feature Extraction
For text, the paper evaluates several embedding models, including text-embedding-small, text-embedding-large, text-embeddings-004, text-embeddings-005, NV-Embed, KaLM, and Stella. For audio, it compares Whisper-base, Whisper-small, Whisper-large, Whisper-large-turbo, wav2vec, and wav2vec-large. Video analysis uses the pre-extracted feature space from OpenFace. After embedding evaluation, the study applies CNN, BiLSTM, and CNN-BiLSTM architectures to learn spatial and temporal patterns from modality-specific embeddings before final classification.
The following flowchart visually represents the entire methodology used in the paper:
This diagram shows the complete workflow—from modality-specific preprocessing (text, audio, and video) to chunking, embedding, fusion, and final assessment. Each component highlights the modular use of embedding models and decision-level fusion with LLM + SVM, leading to high-accuracy predictions.
Results
A comparative assessment of Multilayer Perceptron (MLP) and Support Vector Machines (SVM) classifiers was conducted. Fusion techniques were explored:
Data-Level Fusion: Combined modalities before feature extraction.
Feature-Level Fusion: Concatenated embeddings from each modality.
Decision-Level Fusion: Aggregated individual modality predictions, enhanced by integrating LLM outputs.
Results
The results show that text was the strongest single modality in this study. The best overall system achieved 92.4% balanced accuracy for depression and 88.1% balanced accuracy for PTSD, with strong gains from chunked QA formatting, deep feature extraction, and SVM-based classification. The paper also reports that text-embedding-small was the best-performing text embedding model, while Whisper-small and Whisper-large-turbo were the strongest audio embedding choices for depression prediction. Overall, the findings show that modality-specific preprocessing and classifier design have a major effect on performance.
Comparison with State-of-the-Art Methods
The paper compares its results with a prior LLM-only approach based on Gemini 1.5 Flash, which achieved 77.7% for depression and 80% for PTSD. In contrast, the proposed framework reached 92.4% for depression and 88.1% for PTSD, corresponding to improvements of 14.7 percentage points and 8.1 percentage points, respectively. This comparison highlights the advantage of combining embedding-based multimodal modeling, deep feature extraction, and SVM-enhanced classification over a more limited LLM-only setup.