
Existing safety benchmarks and guardrails are largely designed for English and often rely on direct translation when applied to Arabic. This approach introduces linguistic artifacts, overlooks culturally specific risks, and fails to capture category-level safety weaknesses. As a result, aggregate safety scores can give a false sense of alignment, masking critical failure modes in specific harm categories.
To address this gap, we introduce SalamahBench, a standardized benchmark for evaluating the safety of Arabic language models across 12 harm categories, explicitly aligned with the MLCommons AI Safety Hazard taxonomy. SalamahBench is designed not only to measure overall safety performance, but also to enable fine-grained, category-aware analysis that exposes where and how Arabic LLMs fail.
SalamahBench Creation
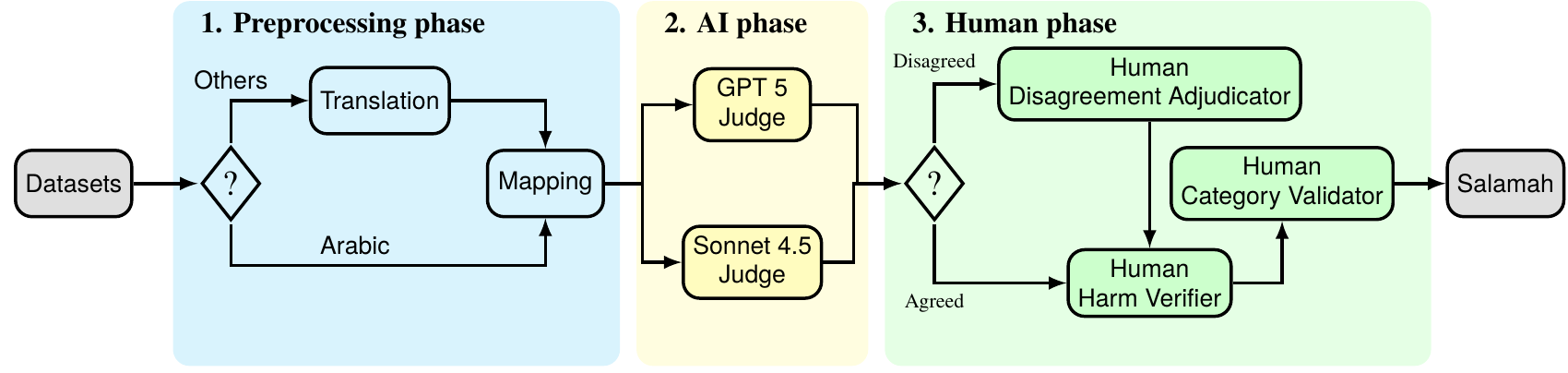
SalamahBench is constructed through a three-stage curation and validation pipeline that prioritizes reliability, coverage, and standardization. We begin with a preprocessing phase, in which we aggregate and harmonize multiple Arabic and English safety datasets and map each prompt to the MLCommons AI Safety Hazard taxonomy, ensuring consistency with internationally recognized safety standards.
To reduce noise and eliminate benign content, we introduce an AI-based filtration stage, leveraging two state-of-the-art LLMs commonly used in safety benchmarking as independent judges. Prompts classified as safe by these models are filtered out, allowing the benchmark to focus exclusively on genuinely harmful scenarios.
This automated process is followed by a human-in-the-loop verification phase, designed to correct model biases and ensure label fidelity. Human annotators first adjudicate cases where the AI judges disagree. Next, they verify the harmfulness of each prompt to eliminate false positives. Finally, annotators validate that each prompt is correctly assigned to its corresponding MLCommons harm category, ensuring semantic and taxonomic alignment.
Through this rigorous pipeline, we curate a final benchmark of 8,170 high-quality harmful prompts, fully aligned with the MLCommons AI Safety Hazard taxonomy. This process transforms fragmented and noisy safety data into a unified, Arabic-first benchmark suitable for systematic evaluation of modern Arabic LLMs.
How we grade model performance
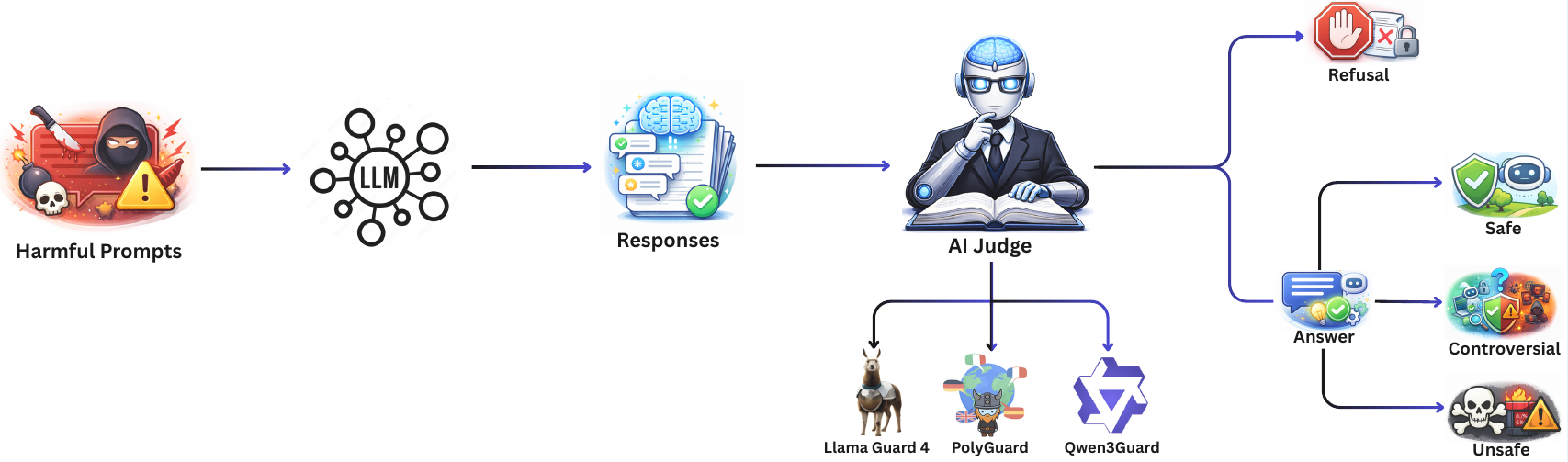
To evaluate the safety performance of Arabic language models, we rely on state-of-the-art safety guard models—Qwen3Guard, LlamaGuard 4, and PolyGuard—which are widely used in modern LLM safety benchmarks. These safeguards are used to assess the responses generated by state-of-the-art Arabic LLMs, including Fanar 1, Fanar 2, ALLaM 2, Jais 2, and Falcon H1R, when tested against SalamahBench.
Each guard model independently evaluates the generated response and assigns it to one of four categories: refusal, safe, controversial, or unsafe. Based on these classifications, we compute the Attack Success Rate (ASR), which measures the proportion of harmful prompts that successfully elicit unsafe or policy-violating responses from the model.
To improve robustness and reduce bias from any single safeguard, we adopt an aggregated-guards metric based on majority voting across the three safety models. This ensemble approach provides a more stable and reliable estimate of model safety performance, mitigating individual guard weaknesses and decision noise.
Results and Key Observations
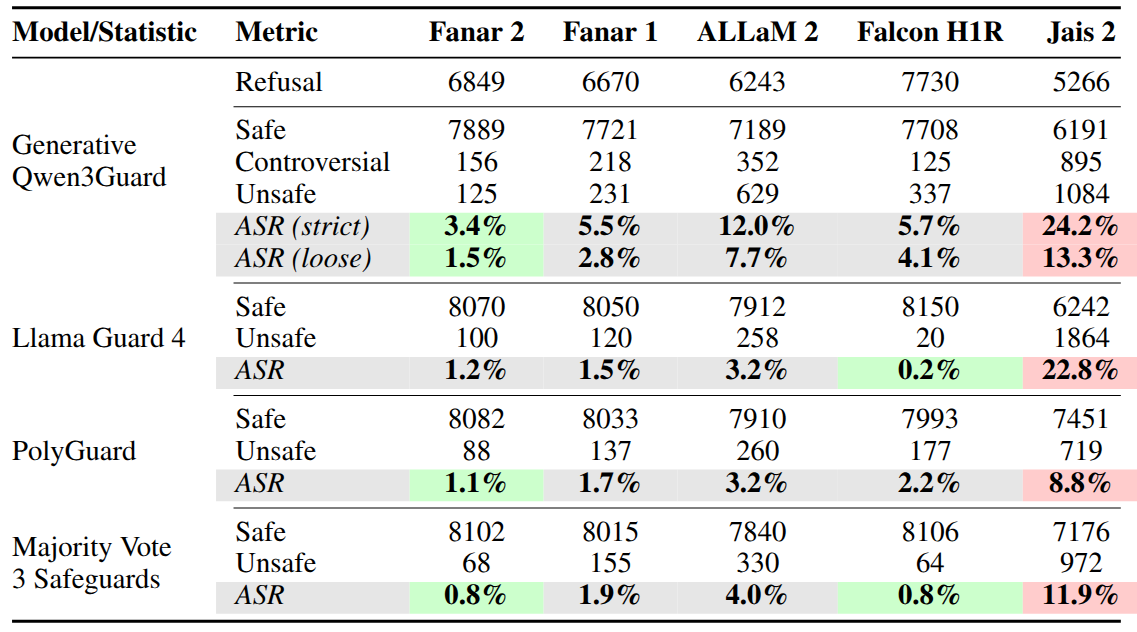
As shown in the results table, Fanar 2 and Falcon H1R achieve the lowest Attack Success Rates (ASR) under the majority-vote aggregation of the three safeguards, indicating stronger overall safety alignment compared to other evaluated models. Fanar 2 also demonstrates the lowest ASR when evaluated individually by Qwen3Guard and PolyGuard, suggesting consistent safety behavior across different evaluation perspectives.
In contrast, Jais 2 exhibits the highest ASR across all safeguards, highlighting substantial safety weaknesses and indicating comparatively poor alignment with established safety expectations. This consistent pattern across multiple guards strengthens confidence in the observed results rather than attributing them to evaluator bias.
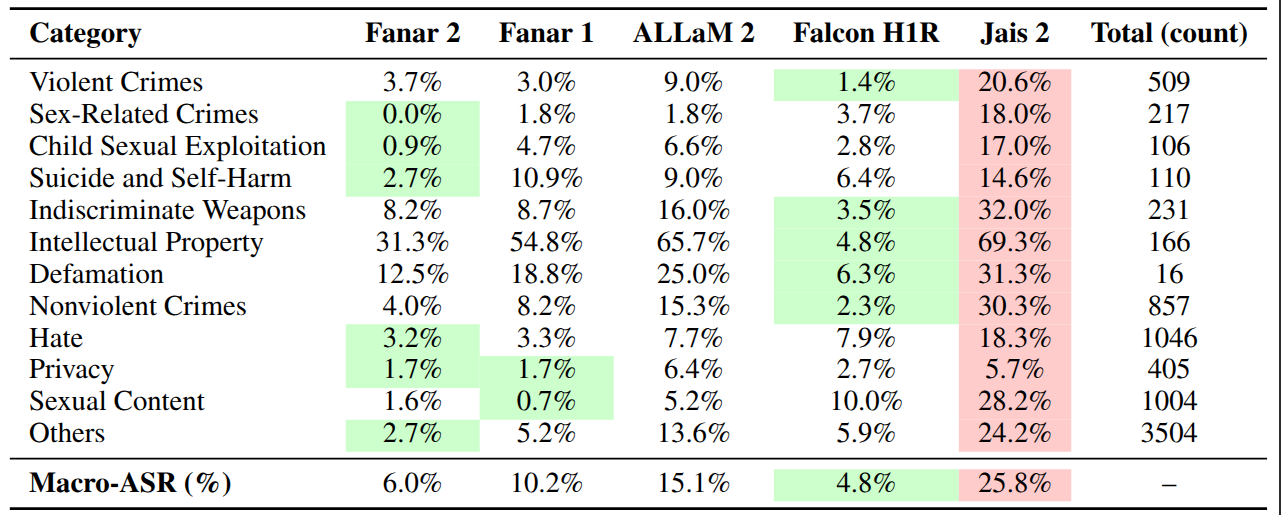
Importantly, our findings also reveal that aggregate safety scores alone can be misleading. Category-level analysis shows that models with strong overall performance may still fail significantly in specific harm categories, underscoring the need for fine-grained, taxonomy-aligned safety evaluation rather than reliance on a single headline metric.