The global mental health crisis continues to challenge healthcare systems worldwide, and the Arab world is no exception. With high prevalence rates of conditions like stress, depression, and anxiety, coupled with a significant shortage of trained mental health professionals, there’s an urgent need for innovative, accessible, and culturally sensitive support tools. At Compumacy, we believe Artificial Intelligence, particularly Large Language Models (LLMs), holds immense promise in bridging this gap.
However, applying LLMs effectively in the Arabic context presents unique hurdles, including limited high-quality labeled datasets, the rich linguistic complexity of Arabic, and potential performance variations when using translated materials. To address these challenges and pave the way for reliable AI-driven mental health solutions, Compumacy embarked on a comprehensive research initiative. Our latest paper, “A Comprehensive Evaluation of Large Language Models on Mental Illnesses in Arabic Context,” dives deep into these issues.
Why This Matters: The Need for Rigorous Evaluation
While LLMs have shown promise in English-speaking contexts for identifying signs of mental distress, their efficacy in Arabic requires careful, systematic evaluation. We need to understand how these powerful tools perform with native Arabic data, how they respond to different prompting strategies, and how language nuances and translation impact their diagnostic capabilities. This understanding is critical for building AI tools that are not just technologically advanced but also genuinely helpful and trustworthy for Arabic-speaking populations.
Our Approach: A Deep Dive into LLM Performance in Arabic
Our research set out to rigorously evaluate a diverse range of LLMs on various mental health assessment tasks using Arabic data. Here’s a glimpse into what we investigated:
- Broad Model Spectrum: We tested 8 LLMs, including widely-used multilingual models and models with a specific focus on Arabic, to assess their performance.
- Diverse Arabic Datasets: Our evaluation spanned multiple datasets covering conditions like depression, anxiety, and suicidal ideation, using both native Arabic content and translated English corpora.
- The Art of Asking: Prompt Engineering: We explored how the way we “ask” the LLM (prompt design) influences its accuracy, comparing two distinct prompt styles for each task.
- Language & Translation Impact: We meticulously analyzed performance differences when models processed native Arabic, translated English-to-Arabic content, and even Arabic content translated into English (while keeping the prompts in Arabic to isolate data language effects).
- Learning from Examples: Few-Shot Prompting: We tested whether providing LLMs with a few examples could significantly boost their diagnostic accuracy.
How We Did It: Our Experimental Setup
We designed a comprehensive experimental framework:
- Dataset Curation: We gathered publicly available native Arabic datasets related to mental health (like AraDepSu, DCAT, and MDE) and also translated well-known English datasets (such as Dreaddit and MedMCQA) into Arabic using Google Translate to broaden our testing scope and study the effect of translation.
- Model Selection: Our lineup included models like Phi-3.5 MoE, GPT-4o Mini, Mistral NeMo, and Arabic-centric models such as Jais 13B and Aya 32B.
- Prompt Variations: For each task (binary classification, multi-class classification, severity prediction, and medical MCQs), we crafted two prompt styles. One was more structured, while the other was less structured and included a “role-play” element, asking the model to “act as a psychologist.”
- Language Configurations: We ran experiments where both the user’s post and our instructional prompt were in Arabic, where English posts were assessed with Arabic prompts, and where Arabic posts were translated to English but still assessed with Arabic prompts.
- Evaluation Metrics: We used Balanced Accuracy (BA) to ensure fairness with imbalanced data and normalized Mean Absolute Error (MAE) for severity prediction tasks to allow for comparison across datasets with different severity scales.
Key Discoveries: What Our Research Unveiled
Our findings offer crucial insights for developing effective AI-driven mental health tools for the Arab world:
- Prompt Design is Paramount: How we frame our questions to the LLM significantly impacts its ability to follow instructions and, consequently, its accuracy. Our more structured prompt (ZS-2) notably outperformed the less structured, role-playing prompt (ZS-1) on complex multi-class diagnostic tasks, improving balanced accuracy by an average of 14.5%, primarily by reducing instruction-following errors. The figure below shows performance of models on different datasets. Each cell contain the performance of ZS-1 on top, ZS-2 in the middle, and the relative improvement percentage at the bottom. Orange represents ZS-1 being better than ZS-2, and blue represents ZS-2 being better than ZS-1.
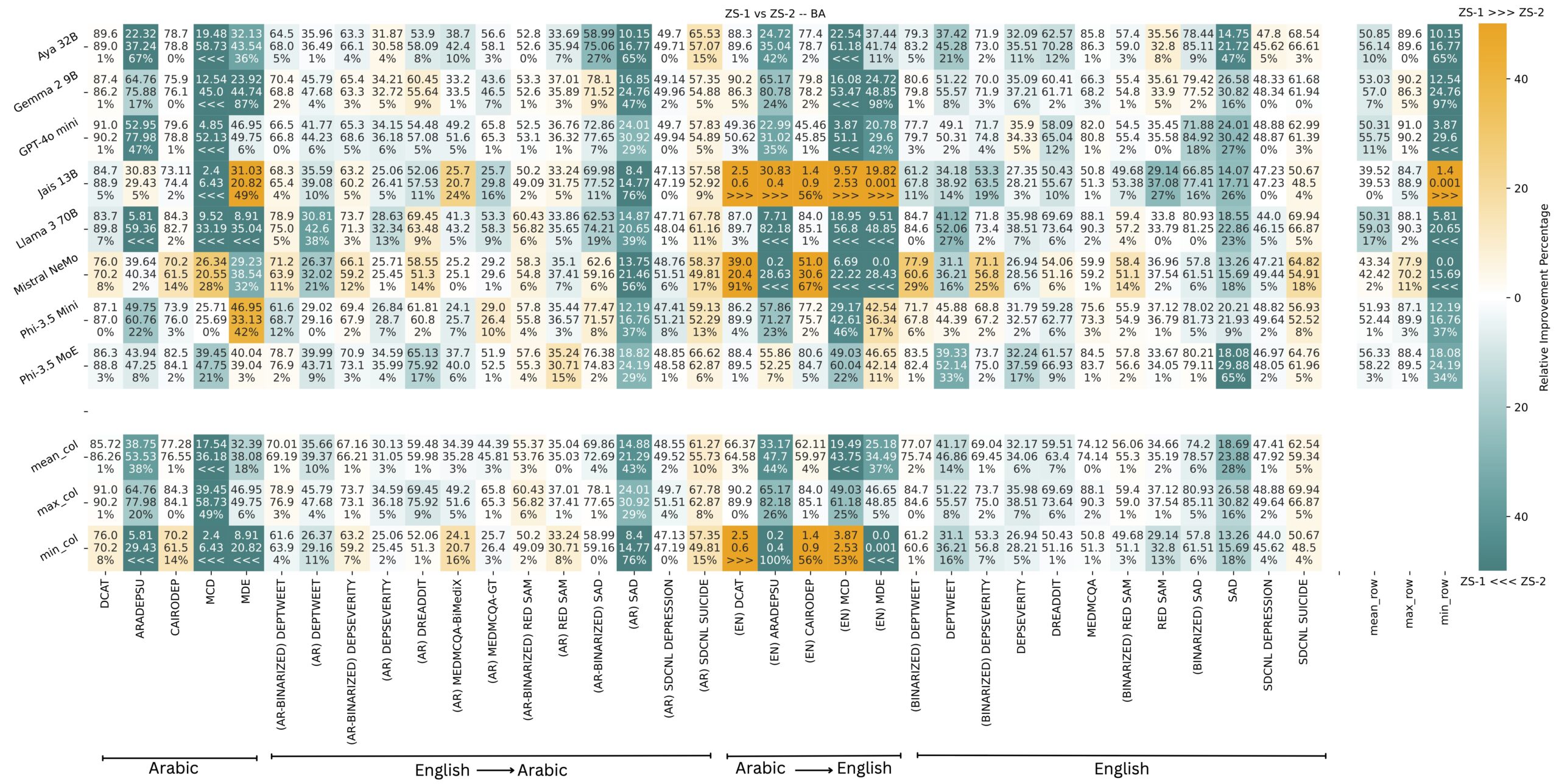
2. The Right Model for the Job: Model selection proved critical.
- Phi-3.5 MoE emerged as a top performer in balanced accuracy, particularly for classification tasks, scoring 4% higher than the second-best model (Gemma 2 9B) and >20% higher on the worst performing (Jais 13B!) on the Arabic datasets.
- Mistral NeMo showed superior performance in predicting the severity of conditions (Mean Absolute Error), scoring a normalized MAE 0.4 lower than the second-best model (Phi-3.5 MoE) on the Arabic datasets.
3. Language Nuances Matter, But It’s Complicated:
- Models performed better on original English datasets compared to their Arabic translations (when prompts matched the data language) on classification tasks, while on severity tasks, there wasn’t a clear winner.
- Interestingly, when native Arabic datasets were translated to English but assessed using Arabic prompts, the original Arabic data often led to better performance for several models, suggesting that translation quality and the model’s proficiency in the prompt’s language are highly influential.
- The figure below shows the relative performance difference when directly inferring on the original dataset language (English) vs after translating it to Arabic and using an Arabic translated prompt (blue indicates that English is better and orange indicates that Arabic is better).
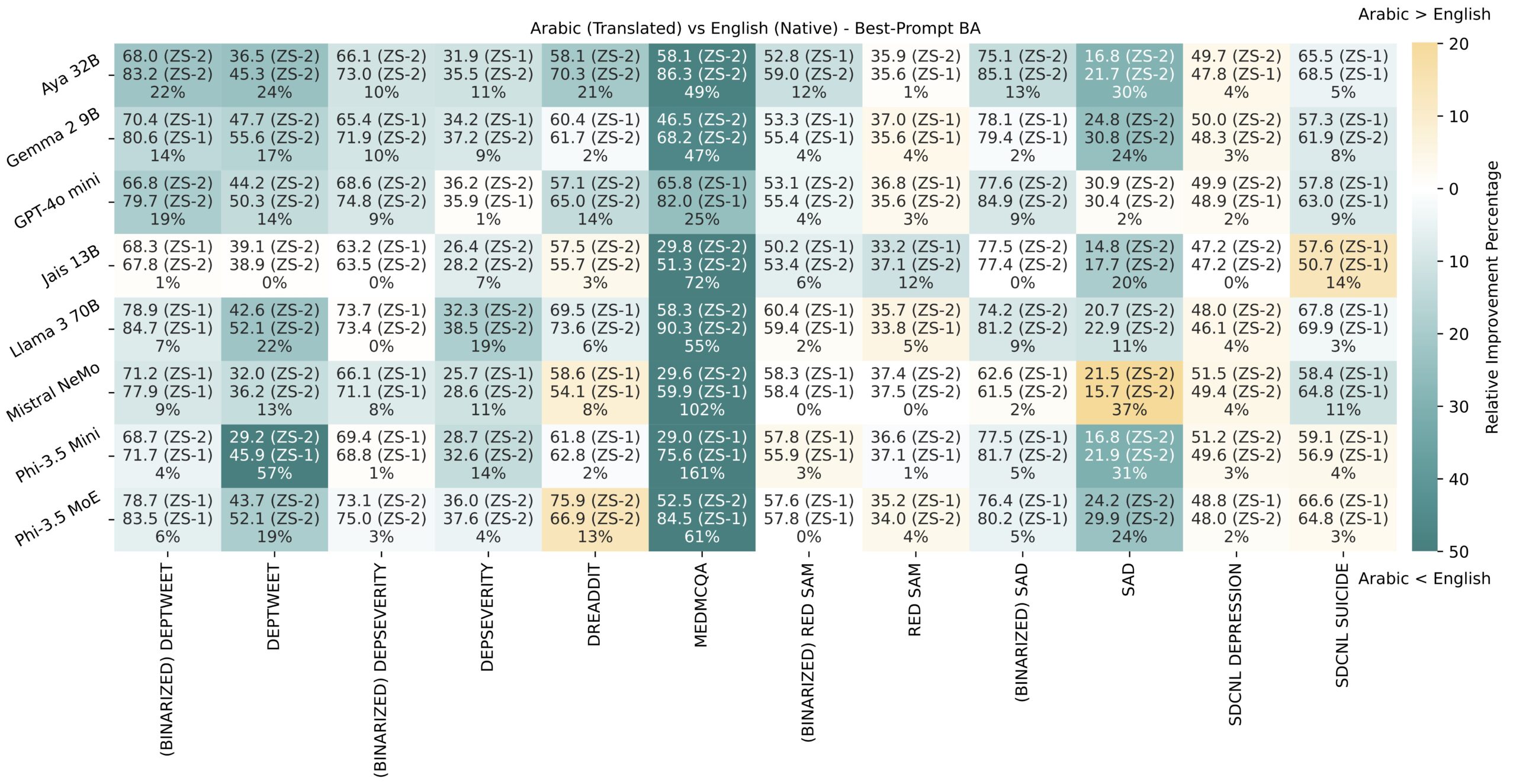
4. A Little Guidance Goes a Long Way (Few-Shot Prompting): Providing LLMs with just a few examples (few-shot prompting) consistently improved performance. This was especially dramatic for GPT-4o Mini on multi-class classification, where accuracy was boosted by an average factor of 1.58 (a 57.6% absolute increase in BA)!
Looking Ahead: The Future of AI in Arabic Mental Healthcare
Our work at Compumacy is ongoing. Future directions include:
- Exploring cutting-edge automated prompt engineering techniques.
- Investigating the potential of fine-tuning promising models on high-quality, domain-specific Arabic datasets.
- Developing methods to enhance the interpretability of LLM diagnoses.
- Exploring machine learning and RAG solutions.
We are committed to pushing the boundaries of AI to create solutions that make a tangible difference in people’s lives.
Dive Deeper into Our Research
We invite you to read our full paper for a detailed account of our methodology, datasets, and comprehensive results:[https://arxiv.org/abs/2501.06859: A Comprehensive Evaluation of Large Language Models on Mental Illnesses in Arabic Context]
How to Cite This Work: