
The increasing global prevalence of mental disorders like depression and PTSD has highlighted severe limitations in traditional clinical assessments, such as subjectivity, recall bias, and limited access to professional healthcare. Over one billion people worldwide suffer from mental health conditions, exacerbated notably during the COVID-19 pandemic, underscoring the need for scalable, objective, and accessible diagnostic tools. Multimodal Machine Learning (MMML), integrating text, audio, and video data, emerges as a transformative approach, addressing these clinical challenges by providing comprehensive diagnostic insights through automated methods.
Main Contributions
This paper offers several key contributions to the field of mental health diagnostics through MMML:
- Comprehensive Modality Analysis: Detailed exploration of preprocessing and formatting strategies, including novel chunking and utterance-based methods for text, audio, and video data.
- Embedding Model Evaluation: Rigorous assessment of multiple state-of-the-art embedding models for accurate representation of multimodal data.
- Advanced Feature Extraction: Deployment of Convolutional Neural Networks (CNNs) and Bidirectional LSTM (BiLSTM) networks to capture contextually rich patterns.
- Fusion Strategies: Comparative analysis of data-level, feature-level, and decision-level fusion techniques, notably incorporating Large Language Model (LLM) predictions.
- Severity and Multi-class Prediction: Expansion beyond binary classification, predicting severity (PHQ-8, PCL-C scores) and multi-class scenarios involving co-occurring conditions.
Methods
Data and Preprocessing
The Enhanced Distress Analysis Interview Corpus (E-DAIC)[1] dataset was employed, featuring text, audio, and video modalities from semi-clinical interviews. Transcriptions were refined using Whisper v3 and Gemini 2.0 for error correction and chunking. Audio segments aligned with textual timestamps, while video features utilized pre-extracted OpenFace data.
Embedding and Feature Extraction
Textual data embeddings were evaluated using multiple transformer-based models (e.g., OpenAI’s text-embeddings-small, Google’s text-embeddings-004). Audio embeddings employed models like Whisper-small and wav2vec. CNN and CNN-BiLSTM architectures effectively captured spatial and temporal dependencies across modalities.
The following flowchart visually represents the entire methodology used in the paper:
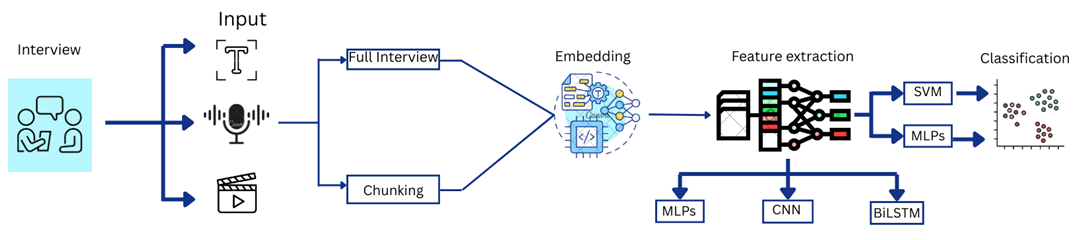
This diagram shows the complete workflow—from modality-specific preprocessing (text, audio, and video) to chunking, embedding, fusion, and final assessment. Each component highlights the modular use of embedding models and decision-level fusion with LLM + SVM, leading to high-accuracy predictions.
Classification and Fusion
A comparative assessment of Multilayer Perceptron (MLP) and Support Vector Machines (SVM) classifiers was conducted. Fusion techniques were explored:
- Data-Level Fusion: Combined modalities before feature extraction.
- Feature-Level Fusion: Concatenated embeddings from each modality.
- Decision-Level Fusion: Aggregated individual modality predictions, enhanced by integrating LLM outputs.
Results
Decision-level fusion incorporating LLM predictions yielded the highest accuracy, significantly outperforming other strategies:
- Depression detection achieved a balanced accuracy of 94.8%.
- PTSD detection reached 96.2% balanced accuracy.
- Severity prediction (MAE) substantially improved, achieving 0.48 for depression and 0.23 for PTSD.
- Multi-class classification balanced accuracy reached 78%, indicating robust model capability for complex mental health scenarios.
Key results are summarized in the following table:
| Task | Best Fusion Strategy | Metric | Performance |
| Depression Detection | Decision-Level + LLM | Balanced Accuracy (BA) | 94.8% |
| PTSD Detection | Decision-Level + LLM | Balanced Accuracy (BA) | 96.2% |
| Depression Severity | Decision-Level + LLM | Mean Absolute Error (MAE) | 0.48 |
| PTSD Severity | Decision-Level + LLM | Mean Absolute Error (MAE) | 0.23 |
| Multi-Class | Decision-Level + LLM | Balanced Accuracy (BA) | 78% |
Comparison with State-of-the-Art Methods
The proposed multimodal approach significantly outperforms existing literature on the E-DAIC dataset for binary classification tasks. It achieves a state-of-the-art accuracy of 94.6% for depression detection and a balanced accuracy of 96.2% for PTSD detection, surpassing previously reported metrics. For severity and multi-class classification tasks, the approach demonstrates considerably lower MAE values for depression (0.48) and PTSD (0.23) and higher balanced accuracy for multi-class classification (78%), compared to the best-performing configurations reported in our previous work[2], which achieved MAEs of 0.60 (Depression) and 0.42 (PTSD) and a balanced accuracy of 34.4% for multi-class tasks.
References
[1] Ringeval, Fabien, Björn Schuller, Michel Valstar, Nicholas Cummins, Roddy Cowie, Leili Tavabi, Maximilian Schmitt et al. “AVEC 2019 workshop and challenge: state-of-mind, detecting depression with AI, and cross-cultural affect recognition.” In Proceedings of the 9th International on Audio/visual Emotion Challenge and Workshop, pp. 3-12. 2019.
[2] Ali, Abdelrahman A., Aya E. Fouda, Radwa J. Hanafy, and Mohammed E. Fouda. “Leveraging Audio and Text Modalities in Mental Health: A Study of LLMs Performance.” arXiv preprint arXiv:2412.10417 (2024).
How to cite this work